
Traditional LLM workflows often rely on rigid, pre-defined logic. While “chat-like” interfaces feel magical, the backend complexity of mapping every user “if-this-then-that” scenario is a maintenance nightmare.
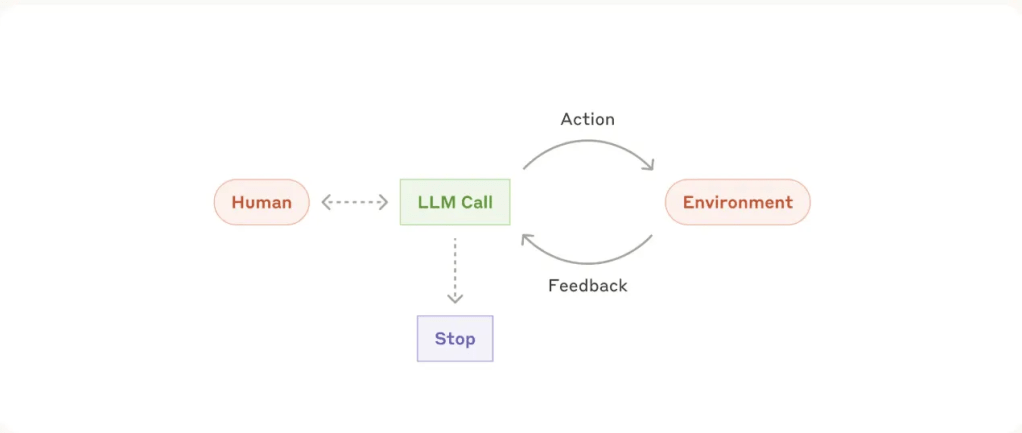
With the rise of LLMs, applications have pivoted toward “chat-like” interfaces. Users can provide free-form text, and the system “magically” determines what information to show or what action to take. To make this magic work, Agents are essential. They use “Chain-of-Thought” (CoT) reasoning to navigate dynamic workflows that are too complex for traditional, rigid “if-then” programming.
However, a more powerful paradigm has emerged: CodeAct (Code as Action). Instead of just talking about tasks, these agents execute them by writing and running code.
What is CodeAct?
Originating from the paper “Executable Code Actions Elicit Better LLM Agents,” CodeAct is a framework where an agent’s actions are consolidated into executable code (typically Python) rather than text-based commands or JSON tool calls.

Instead of just describing what it wants to do, the agent writes a script, executes it in a secure sandbox, and uses the real-world output to inform its next move.
Why Code is Better Than Text
LLMs are exceptionally good at writing code, often more so than following complex nested logic in natural language. Consider the task of “reversing a massive list of strings”:
- Text/JSON Action: The agent will produce token by token, increasing the risk of hallucinations or formatting errors.
- Code Action: The agent simply writes:
Python print([item[::-1] for item in list_str])
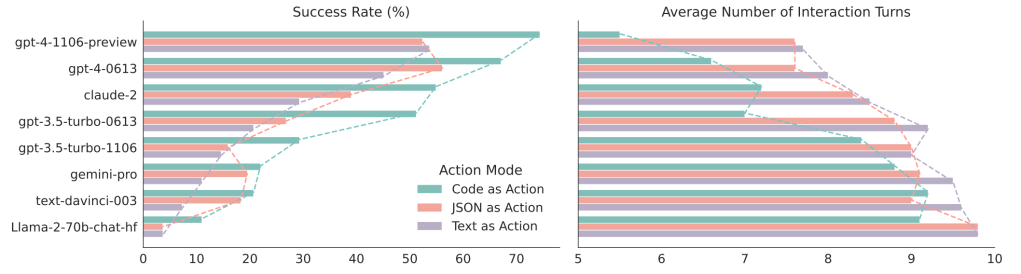
By executing this, the result is guaranteed to be correct. The paper demonstrates that Code as Action achieves a higher success rate and requires fewer iterations to reach a solution compared to “JSON as Action” or “Text as Action.”
The Real-World Edge: Debugging and Complexity
CodeAct shines when tasks get messy. If you ask an agent to find the most cost-effective country to buy a smartphone across four different currencies and tax laws:
- Execution: The agent can use libraries like
pandasfor data orrequestsfor live exchange rates. - Feedback Loops: If the code fails, the agent receives a literal stack trace or error message. These error messages provide much more actionable context than a vague “I couldn’t do that” response, allowing the agent to self-correct and iterate.
The Trade-offs
CodeAct isn’t a silver bullet. There are two main considerations:
- Latency: Running a code execution environment and waiting for the output takes more time than a simple LLM inference.
- Infrastructure: You need a secure, isolated environment (like Docker) to execute the agent’s code safely, which adds overhead to your system. High traffic might cause difficulties in throughput as well.
When should you use it?
CodeAct is ideal for high-precision use cases. If you are building a tool for data analysis, automated software engineering, or complex financial modeling – where a single misplaced semicolon or a slight math error ruins the result – CodeAct is the superior choice.

Leave a comment