
With the influx of AI generation APIs, the way we handle backend requests has fundamentally changed. Unlike traditional APIs, AI generation tasks take significantly longer to process. They often involve intermediate results that can be shared with the user instantly or even require “Human in the Loop” interactions during processing.
I previously worked with image and text models (like BERT) in a synchronous fashion, primarily because of their speed. When using these models for search or ranking, low latency was a hard requirement, and a simple request-response cycle worked perfectly.
However, generative models (like GPT) are different. Because they are autoregressive (producing output token by token) processing a full response takes time. Consequently, the User Experience (UX) of these services has become more interactive. We now see progress indicators, word-by-word streaming, and real-time speech generation.
This shift means system design choices are now tightly tied to service usability. While there are many complex optimizations and communication methods available, here are the three core design patterns you should consider.
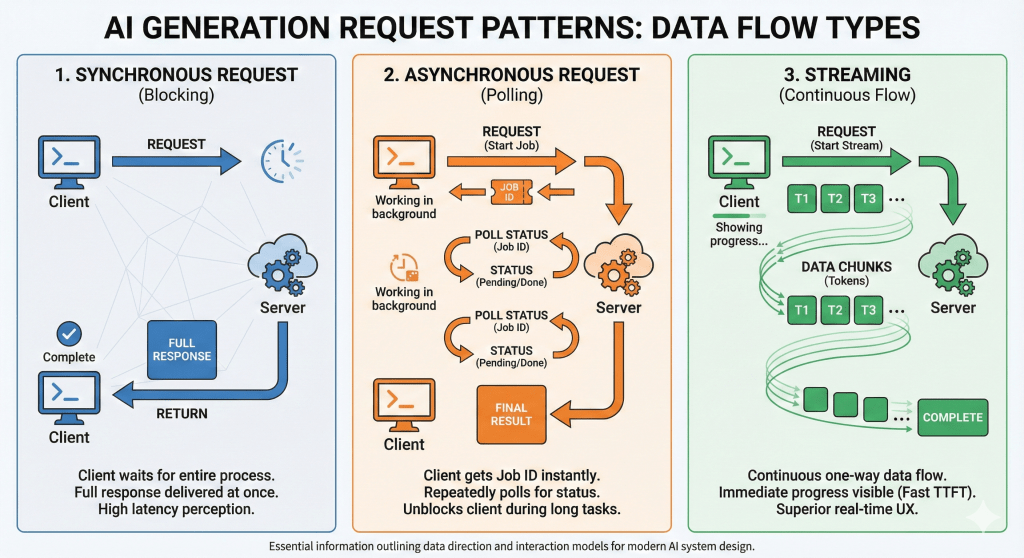
1. Synchronous Request
The standard blocking HTTP call.
Pros
- Simplicity: Easy to implement and integrate with existing REST/gRPC setups.
- Low Overhead: No complex state management or queueing systems required.
Cons
- Timeout Risks: Highly susceptible to HTTP timeouts (e.g., standard 30s gateway limits) if generation takes too long.
- Resource Blocking: Clients must keep connections open, waiting for the full response.
- Perceived Latency: The user stares at a loading spinner until 100% of the work is done.
2. Asynchronous Request (Polling or Webhooks)
Dispatch a job, get a Job ID, and check back later.
Pros
- Reliability: Unblocks the client immediately, preventing timeout errors on long-running tasks (e.g., generating a high-res video).
- Resilience: Enables advanced retry mechanisms. If a job fails, it can be retried from a checkpoint without the user re-submitting.
- Flexibility: Intermediate results can be stored and retrieved later.
Cons
- Complexity: Requires managing a job queue (e.g., Redis/Celery) and state storage.
- Chattiness: Polling can flood the server with status checks; implementing Webhooks reduces this but adds implementation effort.
3. Streaming (The “ChatGPT” Standard)
Push data chunks to the client as they are generated.
Pros
- Superior UX: The user sees progress immediately. This effectively eliminates the “waiting” feeling.
- Faster TTFT: Time to First Token (TTFT) is significantly reduced, making the application feel responsive even if the total generation time is long.
Cons
- Technical Complexity: Requires persistent connections using protocols like Server-Sent Events (SSE) (standard for text) or WebSockets (for bi-directional audio/video).
- Infrastructure Constraints: Load balancers and proxies must be configured to allow long-lived connections without killing them prematurely.
- Error Handling: Handling network interruptions mid-stream is more difficult than retrying a simple failed request.

Leave a comment